How we improved deployment velocity at Cronofy
Deploying smaller changes, more frequently for better system stability
April 7, 2021 · 7 min read
In Q1 2021 I set the goal of increasing the deployment velocity of the Cronofy engineering team. We were already deploying several times per week, often multiple times per day putting us in the top percentile of teams, but I felt we could do better to delivery value more consistently to the business.
A lot had changed in 2020, we’d shifted from two production instances (US, Germany) to five (adding Australia, Singapore, UK) and we were adding a sixth (Canada) during Q1. We were also expanding our internal architecture to include more services. This all increased the complexity of an individual deployment which we had tackled in Q4 2020, but still required an administrator to run a deployment.
This requirement of an administrator getting involved was a point of friction. Even with it being an automated process, it still needed to be requested and waited for. My feeling was this was encouraging the anti-pattern of changes being larger than necessary. Therefore the deal with the team was that I would remove that hurdle and that would enable them to make smaller, more frequent changes.
Why is a higher deployment velocity better?
We all want our systems to be stable and reliable. We all need to change our systems in order to make them more capable, faster, and more resilient. The former seems opposed to change, whereas the latter demands it.
To maximize both these constraints we effectively have two choices:
- Deploy changes infrequently, with long periods of stability
- Deploy changes frequently, with short periods of stability
However, what this does not consider is the risk of each deploy. Deploying infrequently means that more is changing at the same time. The likelihood of a single change including a bug probably doesn’t increase much, if at all, but the network effects of separate changes interacting in unexpected ways increases exponentially.
This makes infrequently deploys inherently more risky due to the size of the batch.
If we accept the size of the batch is an exponent of the risk of a deploy, it follows that the ideal batch size is one. A single change has no other changes to potentially interact with.
This is the promise of continuous deployment. You are deploying more often, but each deployment has nominal risk. This is not free. You have to invest in a deployment pipeline that makes deployments virtually free, otherwise your team would spend the whole time deploying changes. It is, however, an investment that pays back in buckets for what you invest in it.
You will necessarily have automated the whole process, which reduces the mechanical risk of a deployment. You can’t have human errors if there aren’t any humans involved.
The side effect of a higher deployment velocity is a more stable system.
Why are smaller changes better?
If we have dealt with the size of the batch through continuous deployment, the next thing to lean on is the size of each change.
Smaller changes means less is changing, which lowers risk.
However, you do not get the full benefit of this without continuous deployment. Small changes going out in large batches are still subject to the network effect. Without continuous deployment, smaller changes are potentially even introducing overhead to your team.
Smaller changes, going out individually, via an automated process, makes for deployments which are extremely low risk, and very easy to reverse.
Mean time to recovery
Bugs, unfortunately, always happen. With a continuous deployment pipeline in place, which is quickly deploying small changes, your mean time to recovery (MTTR) will be measured in minutes rather than hours or days.
Identifying the culprit for a bug will usually be faster, if a single change was released in the past hour, it’s likely that change is the cause. If the volume is higher, there are still a handful of prime suspects for the investigation.
Through observability you’re likely to find the cause even quicker too.
Through feature flags end users may never experience a bug your internal team does, or the immediate fix will be a straightforward revert.
Regardless of the resolution, the deployment to enact it is inherently low risk due to automation, rather than another opportunity for errors.
Not only do these practices reduce the frequency of deployment-related problems, they minimize the period of instability when they do occur.
How do we measure velocity?
As our process was 99% automated, we had the deployment history going back to mid-2019 when the current deployment pipeline was put in place. Using deployments to our US data center as the proxy for all deployments, we had a long period of historic performance and a good measure for future performance.
With a bit of code and Excel finagling, I could quickly produce a chart showing a four-week moving average of deployments-per-week which I shared with the team.
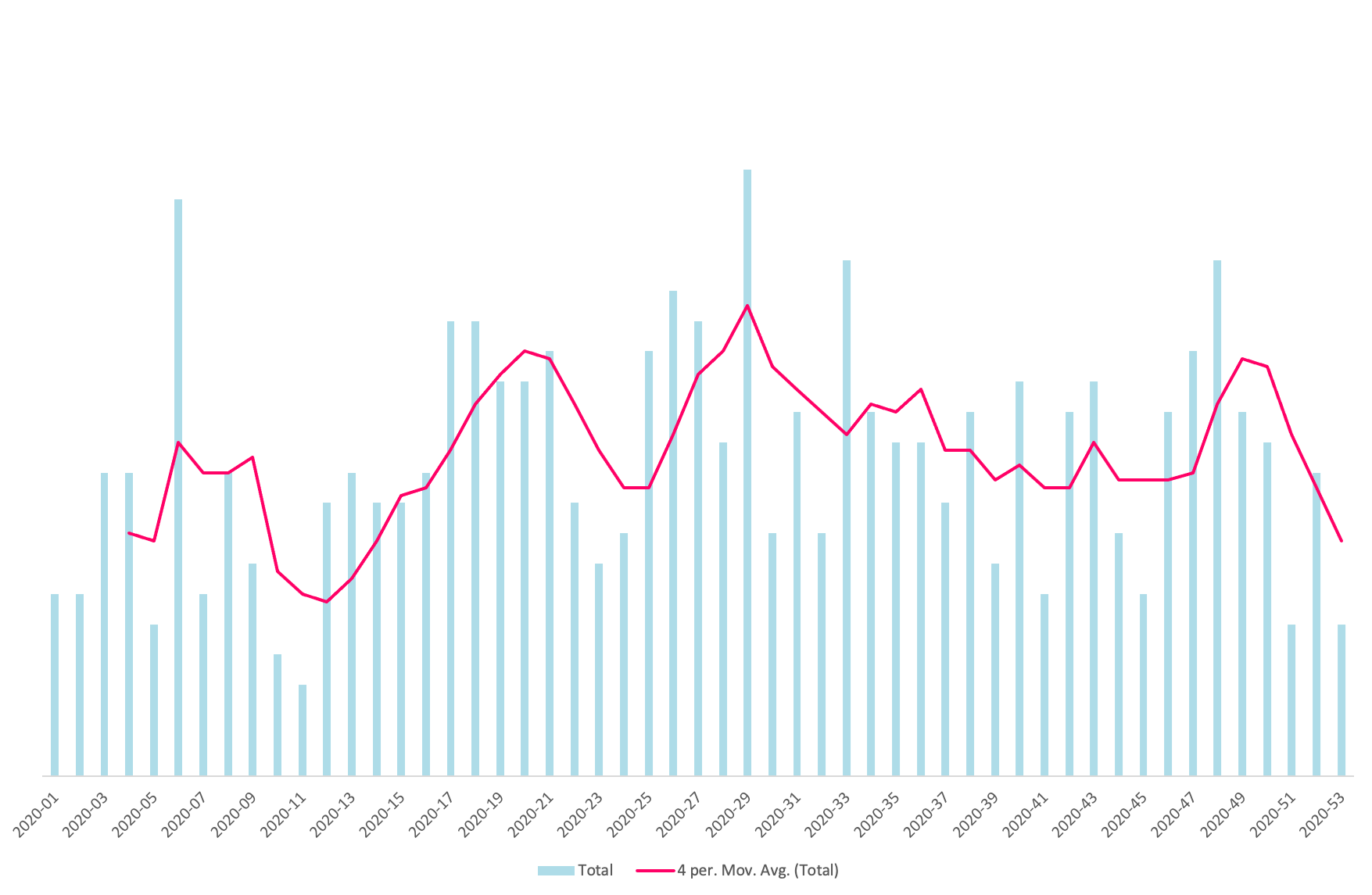
What does good look like?
I was nervous to set a specific target, metrics are inherently game-able, and I did not want to encourage split changes for the sake of hitting some made up number. My hope was for a shift in behavior which could take some time to instill, but would show signs of happening by the end of the quarter.
Full automation
From the work in Q4 2020 to deal with the overhead of more data centers and more services, we had a script we trusted for running a full production deployment. The decision was then how to run the script without an administrator being involved.
My initial thought was towards building a chatbot to shift the process from “can I get a deploy Garry?” to “@rufus deploy”. In the end, I went with triggering from a pull request being merged. This already involved clicking a button, there was no need to add another “button” afterwards! As a bonus this needed less code, and less code is always better.
Rufus reports activity to Slack for oversight and visibility, but is not interactive.
This was a bit of a leap of faith for me, I had grown comfortable with knowing exactly when deployments were happening. With the goal being to provide agency to the team so they would not be impeded by process, I had to let that go.
How did things change?
Somewhat surprisingly, but pleasingly so, the change was almost instant.
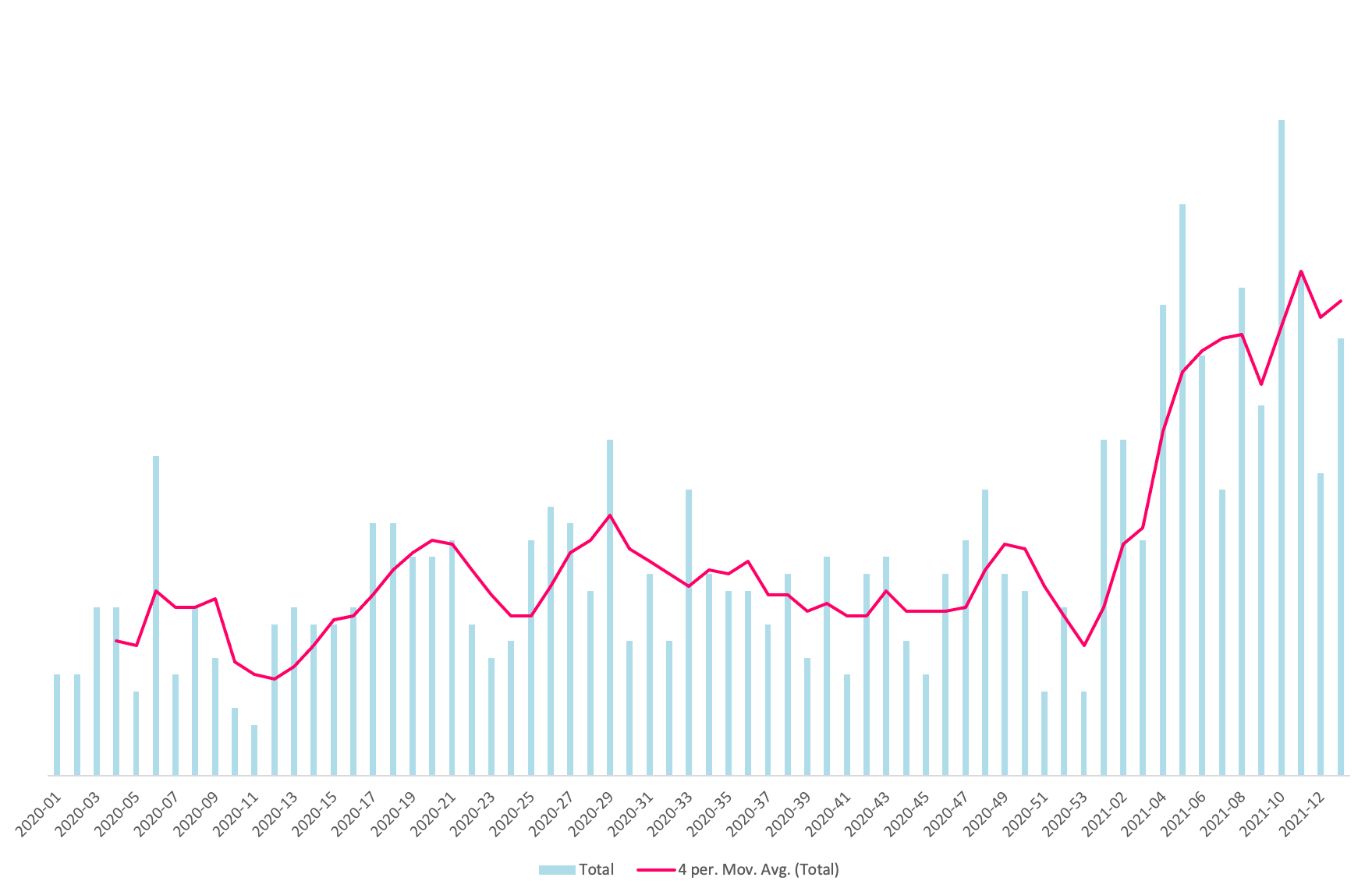
We’ve roughly doubled the number of deployments per week, with a “slow” week being equivalent to a previously “fast” week.
I’ll caveat this to say that a small minority of deployments may not be necessary, for example a change to development environment config, but such deploys are safe. The time required to invest in avoiding such deployments is not worth it compared to the risk of not deploying a change in a timely manner.
I have deliberately stayed away from metrics like lines of code changed, but qualitatively changes are trending towards smaller and I’ve been coaching in approaches to enable smaller changes to be made too. As you can see, the trend appears to be continuing to rise.
The other goal of increased agency for the team has also been achieved:
Now we can spend more time focussed on shipping features rather than running the process itself.
Our pipeline has acquired new features throughout the quarter as a result of questions like “can we make it possible to do X as well?” For example, we’ve made it possible to run things like data backfilling tasks via configuration, think database migrations but for arbitrary scripts. As the scripts have to be source controlled, and the scheduling also goes through source control, this provides the accountability and traceability necessary for our compliance requirements.
Whilst Cronofy’s deployments have always been highly automated, we originally used Heroku for example, we’ve ebbed and flowed with exactly how automated they’ve been. By sharing this, I hope we’ve given a data point that even the step between highly automated and fully automated can reap rewards when it comes to continuous deployment.

Hey, I’m Garry Shutler
CTO and co-founder of Cronofy.
Husband, father, and cyclist. Proponent of the Oxford comma.